AI 干完了普通人能干的活,我们是时候去发展成少数派了
当 AI 模型强到连安全专家的活都接了,普通人凭什么不被替?从模型训练目标出发,理解你的独特性为何不可被拟合。
当 AI 做完了所有人都能做的事,剩下的机会只属于少数派。
一个模型,强到不敢公开
2026 年 4 月,Anthropic 发布了一个新模型 Claude Mythos Preview,但没有面向公众开放。他们做了一件不寻常的事:通过一个叫 Project Glasswing 的计划,把模型优先提供给科技公司和开源维护者,让他们先修掉历史遗留的安全漏洞。
为什么不敢直接放出来?因为这个模型在安全领域的能力跳了一个台阶。上一代模型像一个认真的实习生,你指哪它查哪,偶尔能帮你挑出几个拼写错误。而 Mythos 更像一个干了二十年的老师傅,你把代码丢给它,它自己翻完几千个文件,第二天早上递给你一份报告:这里有个洞,存在 27 年了,所有人都没发现,顺便我写好了修复方案。
这不是实验室数据。它在两周内发现 了 Firefox 浏览器 22 个漏洞,找到了 OpenBSD 一个存在 27 年的 TCP 协议漏洞,找到了 FFmpeg 一个存在 16 年的视频编解码漏洞。这些都是全球顶级安全研究员长年没发现的问题。
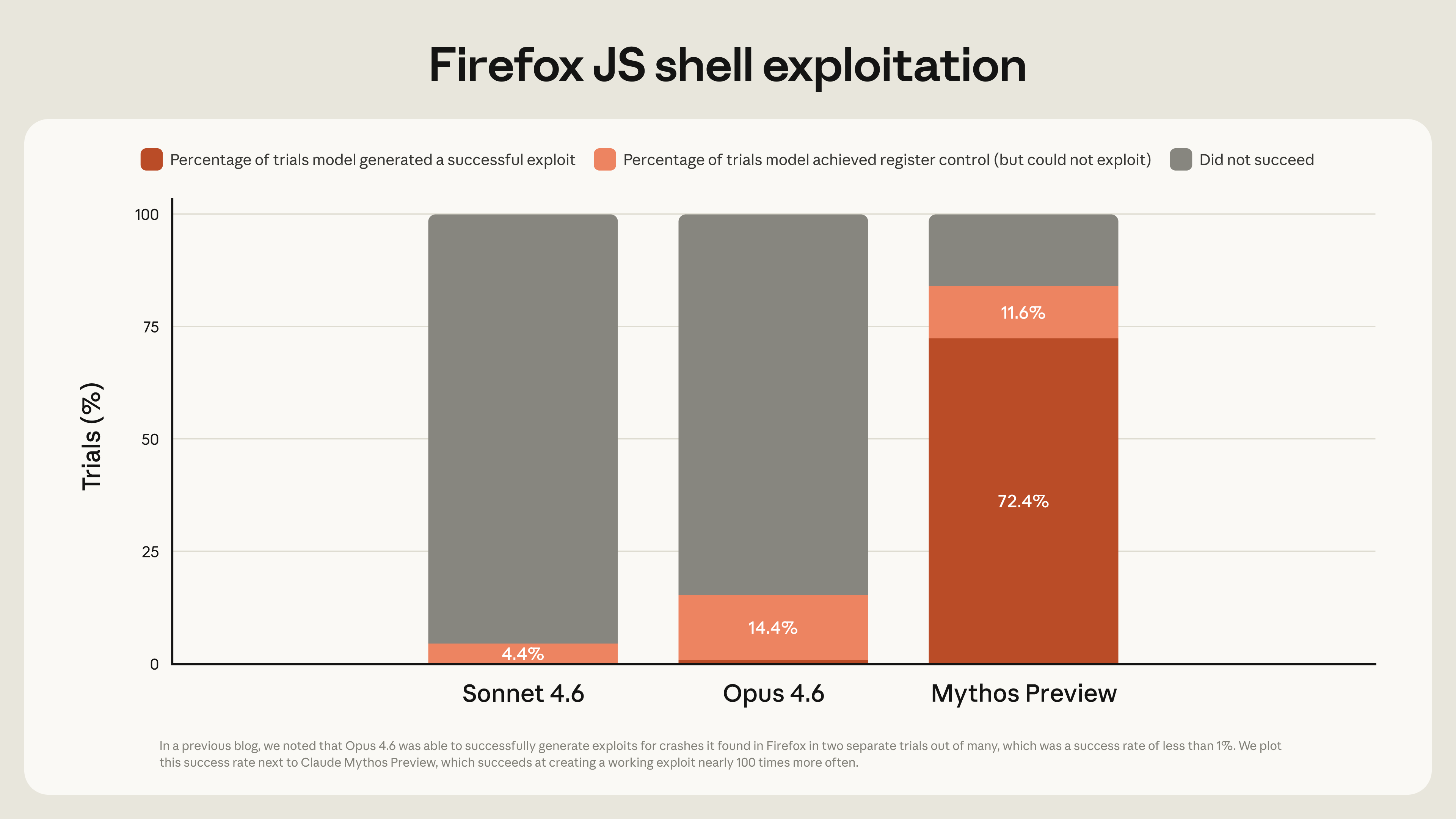
这都指向了一个趋势:至少在软件工程层面,AI 已经把「普通人能做到的」全部做到了,甚至开始侵入「专家才能做到的」领域。
不止软件:各行业的「普通工序」正在被接管
这不是只发生在程序员身上。麦肯锡的报告估计,生成式 AI 可把员工 60-70% 工作自动化掉,在客户运营、营销、软件工程和研发四个领域局势更加紧迫。法律行业的合同审阅、医疗的影像诊断、金融的报告生成、影视的剪辑和特效,都在被快速接管。
共性很明显:凡是有标准流程、有历史数据可学、有「正确答案」可对照的工序,AI 都能学会,而且会越来越快。
问题来了,我们能怎么办?
回到模型的训练目标:它到底在替代什么类型的人?
两年前我写过一篇 大模型下的生存之道,从模型训练目标的角度分析过这个问题。核心逻辑今天依然成立,而且更紧迫了:
模型最核心的优化目标是预测准确性,减小与现实世界的误差,并且要足够通用、足够泛化,不要过拟合。翻译成白话:模型要懂各行各业的共识和通用做法,不要钻牛角尖。麦肯锡在谈不可替代的人类特质时也点到了类似的东西:本能、直觉、想象力、正直、身份认同,这些全是「无法被大数据平均化」的能力。
所以模型天然擅长替代的是通用型输出。而那些带有独特思考角度、独特审美判断、独特经历积淀的人,恰恰是模型不会也不可能替代的。因为要「拟合」一个少数派,模型需要针对你一个人的数据过拟合,这在训练逻辑上没有意义,在资源投入上也不划算。
"异常数据"对模型的通用性伤害是很大的,所以成为"异常数据",或者说成为少数派,就是我们必要做的事情了。
少数派长什么样?
影视行业,AI 能剪辑、能做特效,但诺兰拍《星际穿越》,科幻只是外壳,内核是他自己对亲情和时间的理解,这种东西没有数据集能喂出来。

产品领域,竞品分析 AI 都能出,但能从细分人群的真实痛苦中定义新方向的产品经理,模型学不来。写作领域,通稿 AI 写得又快又好,但带着你亲身经历和价值立场的文章,无法被平均化。教育领域,知识传递 AI 全能干,但能激发学生找到自己路径的导师,是另一回事。
这些人的共性不是「比 AI 更聪明」,而是「输出里带着只有他们才有的东西」。
是时候行动了
如果你看到这里,不妨问自己三件事:
- 我喜欢什么? - 了解你自己
- 我擅长做什么? - 找到你和别人不同的点
- 我经历过什么? - 回忆那些只有你走过的路,踩过的坑,它们就是模型没见过的训练数据
- 我能把这些变成什么? - 把独特性转化成别人愿意买单的输出,而不是藏在心里
然后把这种「少数派」价值放大到极致。不是说不学通用技能,而是在通用技能被模型拉平之后,你拿出来的那个东西,必须是模型再强也没法模仿的。
这就是大模型时代的生存策略。两年前我用「反泛化」「反效率」来描述这件事,今天我想换一个更直接的词:成为少数派。
你觉得自己的「少数派」特质是什么?欢迎留言聊聊。
评论
评论基于 GitHub Discussions,请先 登录 GitHub 后发表评论。